Hunyuan OCR
End-to-end OCR expert vision-language model with native multimodal architecture
What is Hunyuan OCR?
Hunyuan OCR is an end-to-end OCR expert vision-language model developed by Tencent Hunyuan. Built on a native multimodal architecture with only 1 billion parameters, it achieves state-of-the-art results across multiple OCR tasks and benchmarks.

The model combines detection, recognition, parsing, translation, and information extraction into a single unified pipeline. This approach eliminates the need for separate models or complex preprocessing steps, making it simpler to deploy and more efficient to run.
Hunyuan OCR demonstrates strong performance in text spotting, complex document parsing, open-field information extraction, subtitle extraction, and image translation. The model handles multilingual content and complex document layouts with accuracy that matches or exceeds larger models.
The architecture is designed for practical deployment. With 1B parameters, it runs efficiently on modern GPUs while maintaining high accuracy. The model supports both vLLM and Transformers inference paths, giving developers flexibility in how they deploy it.
Hunyuan OCR at a Glance
| Feature | Description |
|---|---|
| Model Name | Hunyuan OCR |
| Category | OCR Vision-Language Model |
| Function | Text Detection, Recognition, Parsing, Translation |
| Parameters | 1 Billion |
| Architecture | Native Multimodal Design |
| Supported Tasks | Text Spotting, Document Parsing, Info Extraction, Translation |
| Inference Options | vLLM, Transformers |
| License | Open Source |
Key Features of Hunyuan OCR
End-to-End Pipeline
Hunyuan OCR combines detection, recognition, parsing, and information extraction into a single model. This eliminates the need for multiple specialized models and reduces deployment complexity. The unified approach also improves accuracy by allowing the model to understand context across all stages of processing.
Lightweight Architecture
With only 1 billion parameters, Hunyuan OCR achieves state-of-the-art results while remaining efficient to run. The model can operate on modern GPUs without requiring excessive memory or compute resources. This makes it practical for both research and production deployments.
Multilingual Capabilities
The model handles multiple languages and complex document layouts. It performs well on multilingual documents, mixed-language content, and various writing systems. This makes it suitable for global applications where documents may contain text in different languages.
Complex Document Parsing
Hunyuan OCR excels at parsing complex documents with tables, formulas, and structured layouts. The model can extract information while preserving formatting, recognize mathematical expressions in LaTeX format, and maintain reading order in documents with complex layouts.
Multiple Deployment Options
The model supports both vLLM and Transformers inference paths. vLLM provides better throughput and lower latency for production deployments, while Transformers offers flexibility for custom operations and debugging. Both paths are well-documented and actively maintained.
Open Source Availability
Hunyuan OCR is available as an open source model, allowing developers to use, modify, and deploy it according to their needs. The open source nature enables transparency, community contributions, and customization for specific use cases.
Why Hunyuan OCR is Different
Most OCR systems today require multiple models working together. A detection model finds text regions, a recognition model reads the text, and separate models handle parsing or translation. Hunyuan OCR combines all these capabilities into a single model, reducing complexity and improving performance.
The model's native multimodal architecture is designed specifically for vision-language tasks. This design choice allows the model to understand both visual and textual information simultaneously, leading to better accuracy on complex documents where layout and content are closely related.
Despite its relatively small size of 1 billion parameters, Hunyuan OCR achieves results that match or exceed much larger models. This efficiency comes from the specialized architecture and training approach, which focuses on OCR-specific tasks rather than general vision-language understanding.
The model performs well across diverse document types including invoices, receipts, ID cards, business cards, and video subtitles. It handles both structured documents with clear layouts and unstructured content where text appears in various orientations and formats.
How to Use Hunyuan OCR?
Get started with Hunyuan OCR in just a few simple steps
Visit the Official Space
Go to the official Hugging Face Space at https://huggingface.co/spaces/victor/HunyuanOCR-EN
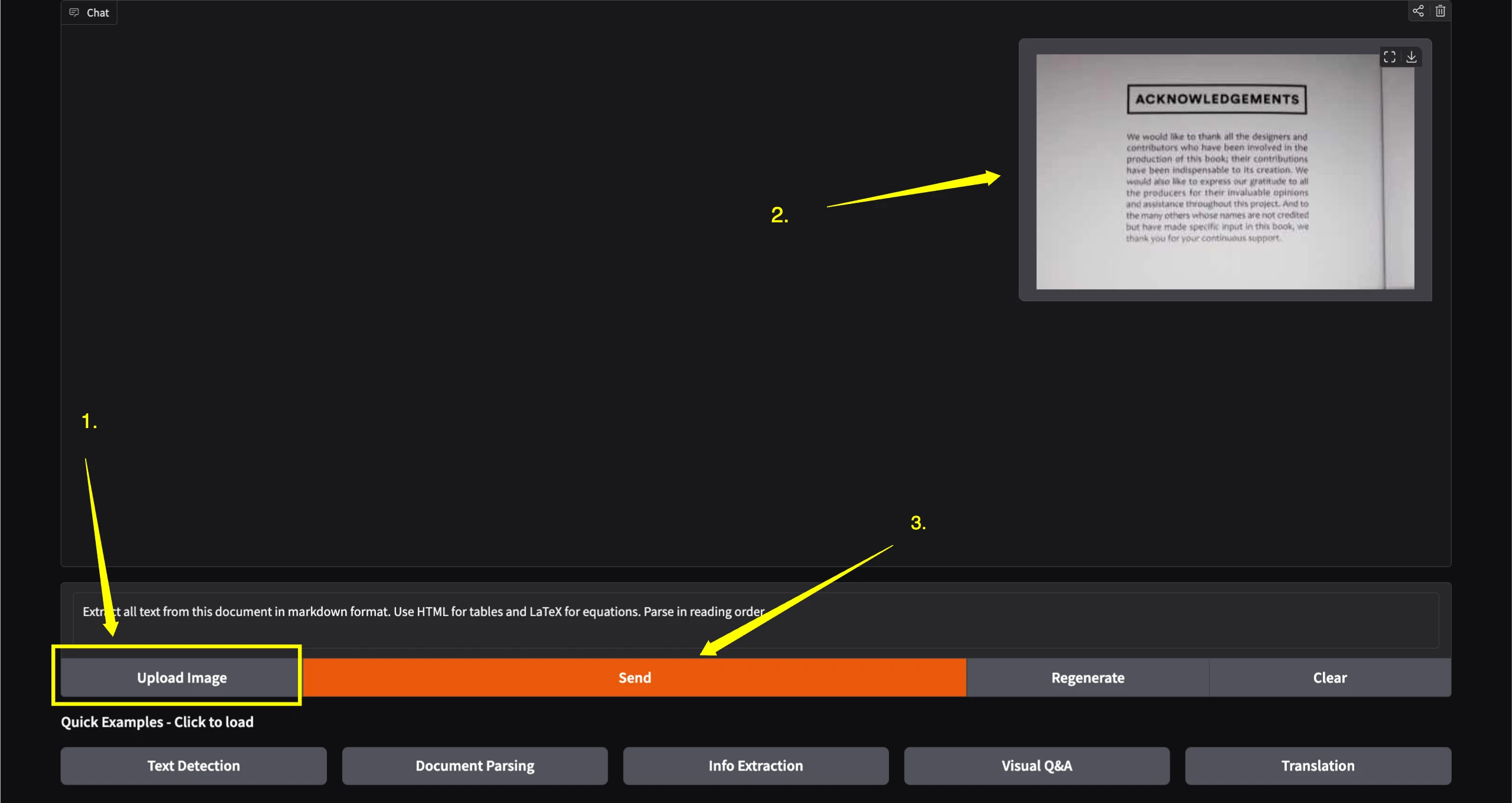
Upload Your Image
Upload the image containing text you want to process. The model supports various document types including receipts, business cards, forms, and images with text.
Click Send
After uploading your image, simply click the "Send" button to process it. The model will analyze the image and provide results based on your task.
Core Features
Text Detection & Recognition
Multi-scene text detection and recognition for various document types and image contexts.
Document Parsing
Automatic document structure recognition that understands layouts, tables, and formatting.
Information Extraction
Extract structured data from receipts, forms, and other documents with complex layouts.
Visual Q&A
Text-centric open-ended question answering about content in images and documents.
Translation
Translate text in images across 14+ languages while preserving document structure.
Performance Benchmarks
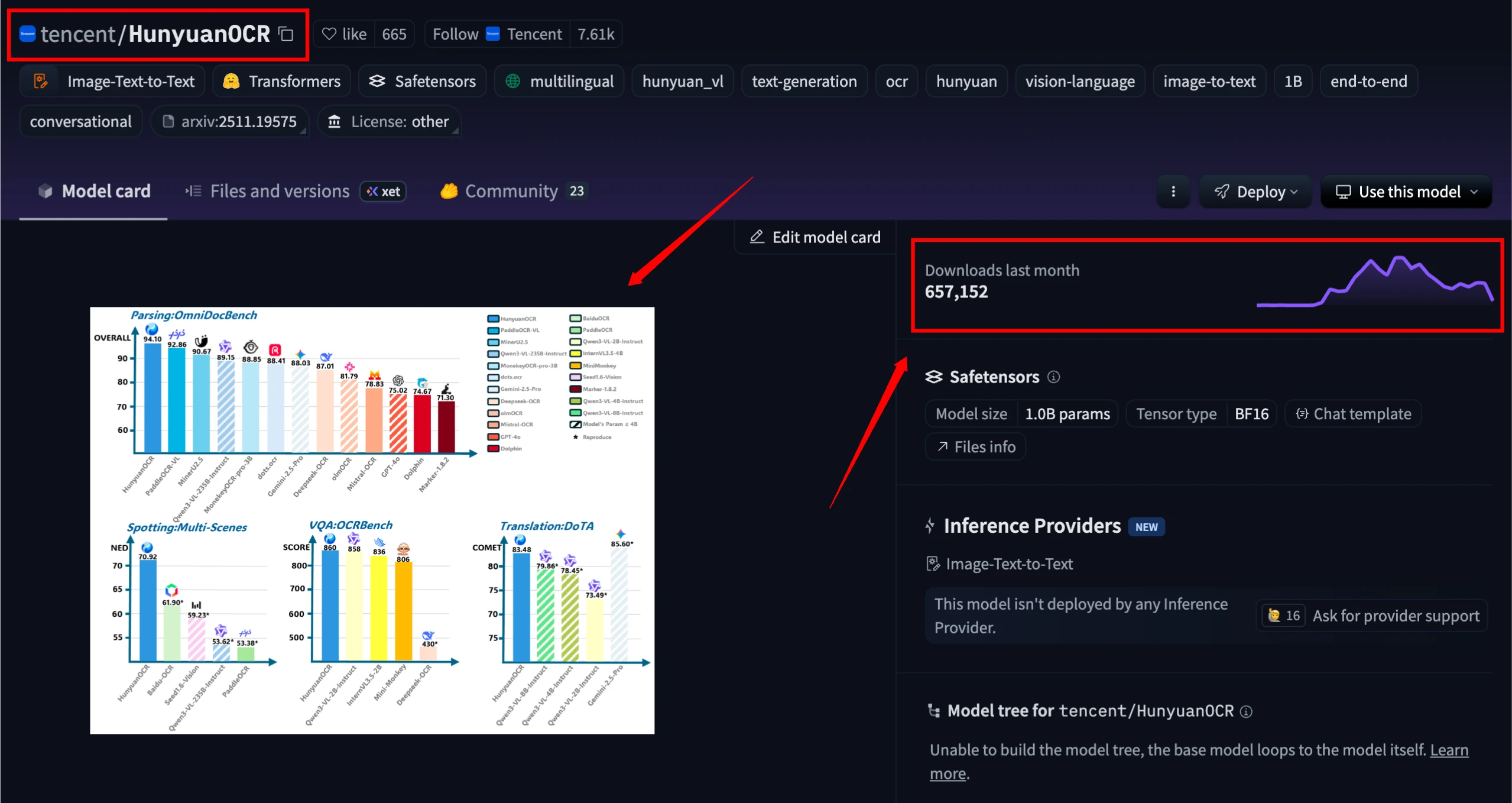
Hunyuan OCR demonstrates strong performance across multiple OCR benchmarks and real-world tasks
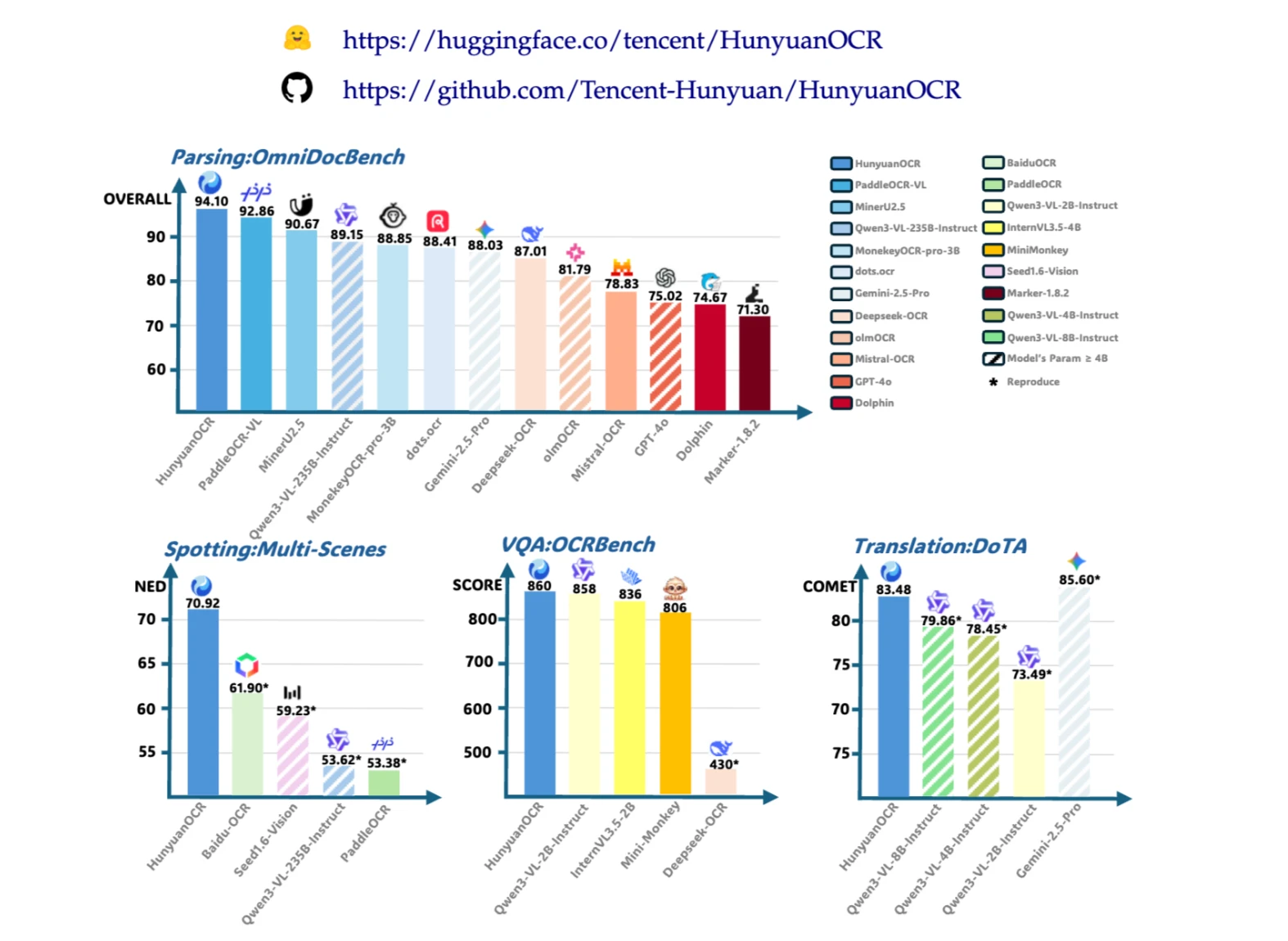
Image credit: https://github.com/Tencent-Hunyuan/HunyuanOCR
Document Parsing Performance
On complex document parsing tasks including business cards, receipts, and video subtitles, Hunyuan OCR achieves accuracy rates above 90 percent. The model outperforms many larger general-purpose vision-language models on OCR-specific tasks.
For business card recognition, the model achieves approximately 92 percent accuracy. On receipt parsing, it reaches around 92.5 percent accuracy. Video subtitle extraction shows similar performance with approximately 92.9 percent accuracy.
Image Translation
Hunyuan OCR performs well on image translation tasks, converting text in images from one language to another. The model handles translation between multiple language pairs while preserving document structure and formatting.
Translation accuracy varies by language pair, with strong performance on common combinations. The model maintains context and formatting during translation, making it useful for multilingual document processing workflows.
Efficiency Metrics
The 1 billion parameter design allows the model to run efficiently on modern GPUs. With proper configuration, the model can process documents with reasonable latency while maintaining high accuracy. The vLLM deployment path provides additional optimizations for throughput.
Memory requirements depend on the deployment method and configuration. For vLLM deployments, 80GB GPU memory is recommended for 16K-token decoding. Smaller configurations are possible with reduced max_tokens or image downsampling.
Try Hunyuan OCR
Experience Hunyuan OCR with the interactive demo below
What You Can Build
Document Digitization
Convert paper documents, forms, and records into searchable digital formats with high accuracy and preserved formatting.
Invoice Processing
Extract structured data from invoices, receipts, and financial documents for automated accounting and expense management.
ID and Form Recognition
Process identification documents, application forms, and official paperwork with accurate text extraction and field recognition.
Multilingual Translation
Translate text in images and documents between multiple languages while maintaining document structure and formatting.
Subtitle Extraction
Extract and process subtitles from video frames and images for content localization and accessibility purposes.
Content Management
Build systems that extract and organize information from documents, enabling search, categorization, and automated workflows.
Technical Architecture
Hunyuan OCR uses a native multimodal architecture designed specifically for vision-language tasks. The 1 billion parameter model processes both visual and textual information through a unified architecture that understands the relationship between images and text.
The model supports multiple inference paths. The vLLM path provides optimized throughput and latency for production deployments. The Transformers path offers flexibility for custom operations and research applications. Both paths support the same model weights and produce consistent results.

Image credit: https://github.com/Tencent-Hunyuan/HunyuanOCR
For optimal OCR performance, the model works best with greedy sampling or low-temperature sampling. Unlike multi-turn chat applications, OCR tasks typically do not benefit from prefix caching or image reuse, so these features can be disabled to improve efficiency.
The model can process documents with various configurations. Maximum token limits, image resolution, and batch sizes can be adjusted based on hardware capabilities and performance requirements. The vLLM deployment guide provides detailed configuration options for different use cases.
Configuration Tips
When deploying Hunyuan OCR, several configuration choices can improve performance and efficiency. Understanding these options helps optimize the model for specific use cases and hardware constraints.
Sampling Configuration
Use greedy sampling with temperature set to 0.0 for optimal OCR accuracy. Low-temperature sampling also works well. Higher temperatures may reduce accuracy for OCR tasks where precision is important.
Caching Settings
Disable prefix caching and image processor caching for OCR tasks. These features are designed for chat applications with repeated prompts, but OCR tasks typically process unique documents where caching provides little benefit.
Token Limits
Adjust max_num_batched_tokens based on your hardware capabilities. Larger values improve throughput but require more GPU memory. Start with default values and adjust based on your specific hardware and performance requirements.
Prompt Design
Well-designed prompts significantly impact OCR results. The official documentation provides application-oriented prompts for various document parsing tasks. Experiment with prompt structure to optimize results for your specific use case.